












 VI
VI
 EN
EN













Nhắn tin qua
Zalo Official

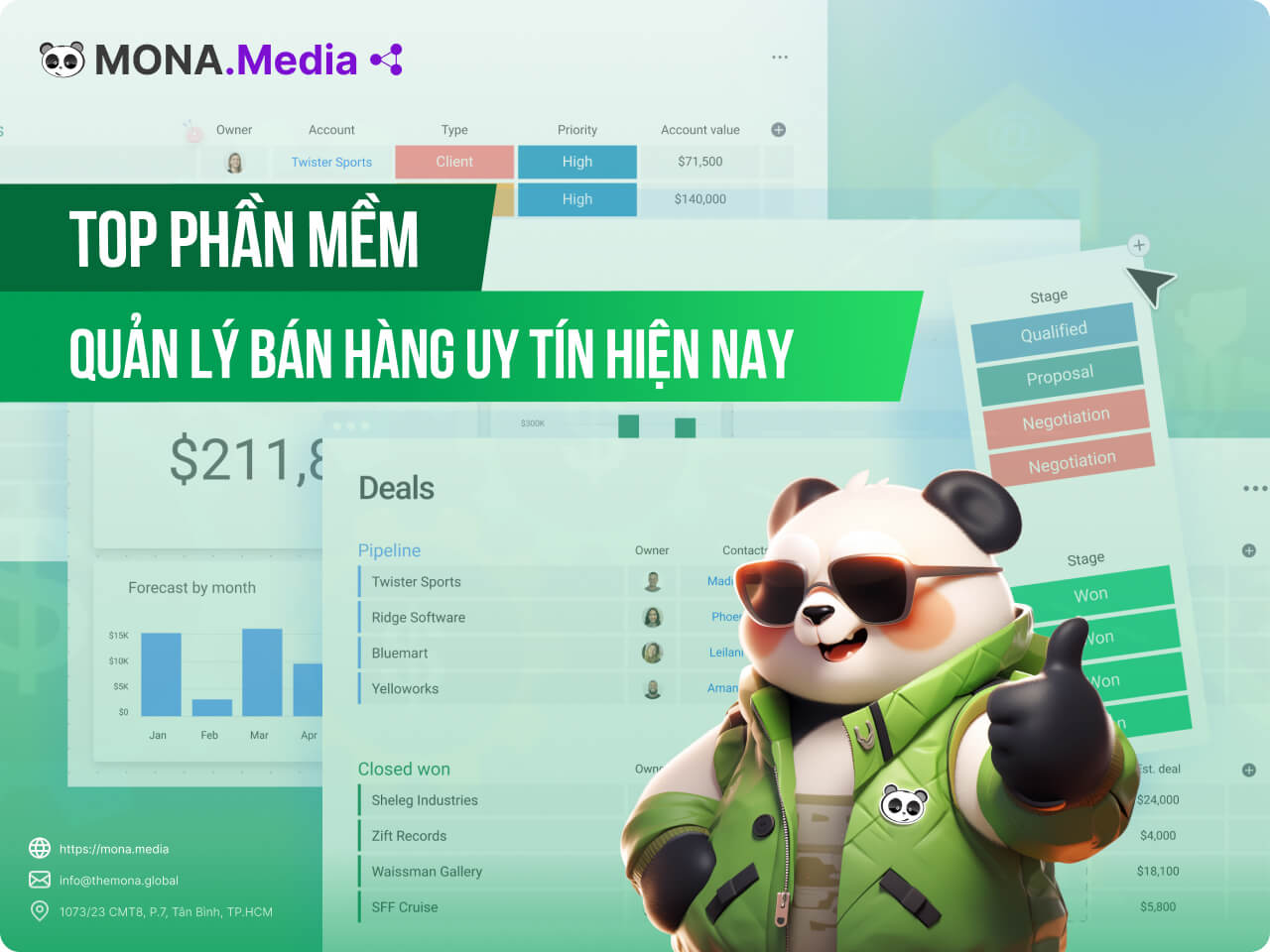
 Sản phẩmSản phẩm
Sản phẩmSản phẩm Thiết kế website PremiumVừa đẹp vừa thuyết phục được khách.
Thiết kế Website AI MớiWeb đẹp có hồn, biết tự bán 24/7.
Thiết kế website PremiumVừa đẹp vừa thuyết phục được khách.
Thiết kế Website AI MớiWeb đẹp có hồn, biết tự bán 24/7.
 Dịch vụ SEO Tối ưu chi phíHút traffic từ khách có nhu cầu sẵn.
Dịch vụ SEO Tối ưu chi phíHút traffic từ khách có nhu cầu sẵn.
 Quay video doanh nghiệpNâng tầm uy tín bằng video chất lượng.
Quay video doanh nghiệpNâng tầm uy tín bằng video chất lượng.
 MONA SkillHubPhần mềm đào tạo nội bộ doanh nghiệp.
MONA SkillHubPhần mềm đào tạo nội bộ doanh nghiệp.
 Hệ thống NHTQTrọn nghiệp vụ vận chuyển Trung – Việt.
Hệ thống NHTQTrọn nghiệp vụ vận chuyển Trung – Việt.
 MONA JMSPhần mềm tiệm vàng, kim cương, cầm đồ.
MONA JMSPhần mềm tiệm vàng, kim cương, cầm đồ.
14 Tháng Sáu, 2026
Trong kỷ nguyên số, khi các công cụ AI ngày càng mạnh mẽ, việc tối ưu website không chỉ dừng lại ở SEO truyền thống. Anh chị chủ doanh nghiệp và các marketer cần hiểu rõ llms.txt là gì để kiểm soát cách các AI crawler thu thập và sử dụng dữ liệu từ trang web của mình. Nếu không khai báo đúng, thông tin quý giá của doanh nghiệp có thể bị sử dụng sai mục đích, thậm chí gây tổn hại đến uy tín và lợi thế cạnh tranh. Tụi em tại MONA Media nhận thấy đây là một nỗi trăn trở lớn, đặc biệt khi anh chị muốn bảo vệ tài sản số và đảm bảo chiến lược marketing hiệu quả trong bối cảnh AI đang định hình lại toàn bộ cuộc chơi.

Một trong những nỗi lo lớn nhất của anh chị chủ doanh nghiệp hiện nay là việc mất kiểm soát thông tin trên internet. Khi AI quét dữ liệu website một cách không chọn lọc, tài sản số của chúng ta có nguy cơ bị sử dụng sai mục đích hoặc làm lộ bí mật kinh doanh.
Đó là lý do vì sao chúng ta cần đến LLMs.txt. Đây không chỉ là một tập tin kỹ thuật đơn thuần, mà còn là công cụ chiến lược giúp anh chị định hướng cách các mô hình ngôn ngữ lớn (LLM) tương tác với nội dung website. Nó đóng vai trò như một tấm khiên, bảo vệ thông tin nhạy cảm, đồng thời là kênh thông tin rõ ràng cho AI crawler.
Các mô hình AI đang ngày càng giỏi trong việc tổng hợp và phân tích thông tin từ khắp mọi nơi trên internet. Điều này mang lại tiện ích cho người dùng, nhưng lại là thách thức lớn cho doanh nghiệp. Một chuỗi bán lẻ thời trang với 20 chi nhánh tại Hà Nội và doanh thu khoảng 40 tỷ/tháng từng chia sẻ với tụi em nỗi lo này. Họ đầu tư rất nhiều vào nội dung độc quyền về xu hướng, chiến dịch marketing, và dữ liệu khách hàng. Nhưng nếu AI quét không kiểm soát, những thông tin đó có thể bị tổng hợp và biến thành “kiến thức chung” cho bất kỳ ai.
Tụi em hiểu rằng anh chị muốn bảo vệ lợi thế cạnh tranh của mình. Việc AI tự do thu thập, phân tích và thậm chí tái tạo nội dung có thể làm mờ đi ranh giới giữa thông tin công khai và tài sản trí tuệ. Đặc biệt, với những doanh nghiệp có quy trình nội bộ, báo cáo tài chính hay các chiến lược kinh doanh được công bố trên website nhưng chỉ dành cho đối tác, việc kiểm soát AI là cực kỳ cần thiết.
MONA luôn nhấn mạnh tầm quan trọng của việc chủ động định hướng cho AI. Chúng ta không thể ngăn AI quét, nhưng hoàn toàn có thể chỉ dẫn chúng quét cái gì, bỏ qua cái gì. Một công ty phần mềm với 35 nhân sự và doanh thu 55 tỷ/năm mà tụi em từng hợp tác, họ có một thư viện tài liệu kỹ thuật khổng lồ. Việc cho phép AI truy cập toàn bộ có thể khiến các bí quyết công nghệ bị rò rỉ. LLMs.txt trở thành giải pháp để họ kiểm soát chặt chẽ vấn đề này.
Nhiều anh chị có thể nghĩ LLMs.txt tương tự như robots.txt, nhưng thực tế chúng có những điểm khác biệt quan trọng. Robots.txt chủ yếu chỉ dẫn các bot của công cụ tìm kiếm (như Googlebot) về việc thu thập dữ liệu để lập chỉ mục. Trong khi đó, LLMs.txt được thiết kế riêng để giao tiếp với các mô hình ngôn ngữ lớn, những AI có khả năng hiểu và xử lý ngôn ngữ tự nhiên phức tạp hơn nhiều.
Tập tin này cho phép anh chị chỉ định rõ ràng hơn về cách AI nên sử dụng dữ liệu. Ví dụ, anh chị có thể cho phép AI đọc các bài viết blog thông thường để tổng hợp thông tin, nhưng cấm chúng truy cập vào các trang chứa báo cáo nghiên cứu thị trường độc quyền hoặc danh sách khách hàng tiềm năng. Một chuỗi phòng khám nha khoa 25 chi nhánh tại TP.HCM, doanh thu khoảng 60 tỷ/tháng, đã dùng LLMs.txt để bảo vệ các nghiên cứu lâm sàng nội bộ và dữ liệu về kỹ thuật điều trị độc quyền của họ. Họ muốn AI học từ các bài viết về sức khỏe răng miệng phổ thông, nhưng không được phép “đọc trộm” các tài liệu chuyên sâu dành cho đội ngũ y bác sĩ.
MONA đã hỗ trợ nhiều doanh nghiệp triển khai LLMs.txt như một phần của chiến lược bảo mật dữ liệu tổng thể. Chúng ta cần hiểu rằng, AI không chỉ đơn thuần là “đọc” mà còn “học” và “sáng tạo”. Vì vậy, việc kiểm soát nguồn dữ liệu đầu vào là bước đầu tiên để đảm bảo AI hoạt động theo đúng mong muốn của chúng ta, bảo vệ tài sản số và duy trì lợi thế cạnh tranh trong thời đại số.


Mỗi CEO, Giám đốc Marketing đều trằn trọc khi công sức xây dựng nội dung, dữ liệu độc quyền trên website có thể bị thu thập mà không hề hay biết. Tình trạng này đang diễn ra từng ngày. Các hệ thống AI mới liên tục quét và “nuốt chửng” thông tin từ hàng tỷ trang web để đào tạo mô hình của chúng.
Chúng ta đang mất dần quyền kiểm soát tài sản số của mình. Dữ liệu quý giá, được đội ngũ anh chị dày công xây dựng, bỗng trở thành “nguyên liệu” miễn phí cho các mô hình ngôn ngữ lớn (LLM). Hậu quả không chỉ dừng lại ở việc mất bản quyền. Nó còn tạo ra rủi ro cạnh tranh không lành mạnh và lộ thông tin nhạy cảm.
Tụi em tại MONA nhận thấy đây là một nỗi đau lớn. Nhiều doanh nghiệp Việt, đặc biệt là các chuỗi có quy mô lớn, đang thiếu cơ chế khai báo rõ ràng. Họ không thể chỉ định phần nào của website được phép, phần nào không được phép AI thu thập. Điều này tạo ra một “lỗ hổng” lớn trong chiến lược bảo vệ tài sản số.
Dữ liệu độc quyền là tài sản quý giá nhất của doanh nghiệp. Đó là những bài viết chuyên sâu, hình ảnh sản phẩm độc đáo, quy trình dịch vụ đặc thù hay các phân tích thị trường chỉ riêng anh chị có. Khi AI thu thập mà không có sự kiểm soát, chúng ta đối mặt với nguy cơ rất lớn.
Một chuỗi nhà hàng 18 chi nhánh tại Hà Nội, với doanh thu hơn 40 tỷ/tháng, đã từng chia sẻ nỗi lo này với MONA. Họ đầu tư rất nhiều vào việc xây dựng công thức món ăn, mô tả hương vị và hình ảnh món ăn trên website thiết kế riêng. Nếu AI dùng những dữ liệu đó để tạo ra nội dung tương tự cho đối thủ, lợi thế cạnh tranh sẽ bị bào mòn.
MONA luôn khuyên anh chị chủ động bảo vệ dữ liệu. Việc để AI tự do đào tạo trên nội dung độc quyền có thể dẫn đến việc các công cụ AI khác tạo ra bản sao. Những nội dung này có thể xuất hiện trên các website đối thủ, hoặc thậm chí là các nền tảng AI tổng hợp, làm giảm giá trị thương hiệu và công sức đầu tư của anh chị.
Chúng ta cần một hàng rào kỹ thuật rõ ràng. Hàng rào này sẽ ngăn chặn các AI crawler sử dụng dữ liệu độc quyền mà không có sự đồng ý. Đó là lý do tụi em luôn nhấn mạnh tầm quan trọng của việc khai báo đúng cách.
Ngoài dữ liệu độc quyền, website của anh chị còn chứa nhiều thông tin nhạy cảm khác. Đó có thể là các điều khoản dịch vụ riêng, chính sách giá đặc biệt cho từng phân khúc khách hàng, hoặc thậm chí là các tài liệu nội bộ không may bị công khai.
Một công ty phân phối thiết bị công nghiệp tại Đồng Nai, với hơn 50 nhân sự và doanh thu xấp xỉ 60 tỷ/năm, từng gặp phải tình huống khó xử. Website của họ có một phần tài liệu kỹ thuật chi tiết dành cho đối tác. Dù đã cố gắng bảo mật, một số AI vẫn có thể truy cập và thu thập nội dung này. Điều này làm lộ các thông số kỹ thuật, quy trình lắp đặt độc quyền mà đáng lẽ chỉ đối tác mới được biết.
MONA hiểu rằng việc kiểm soát thông tin là vô cùng quan trọng. Một khi AI đã thu thập và xử lý, rất khó để hoàn toàn loại bỏ chúng khỏi các mô hình. Thông tin nhạy cảm có thể bị tái tạo, rò rỉ hoặc sao chép. Điều này gây ra những hệ lụy lớn về uy tín và lợi thế cạnh tranh của doanh nghiệp.
Chúng ta cần một cơ chế để “đánh dấu” rõ ràng. Các khu vực chứa thông tin nhạy cảm phải được bảo vệ. Việc khai báo đúng chuẩn giúp AI crawler hiểu và tôn trọng các giới hạn này.
Việc không khai báo rõ ràng quyền truy cập cho AI crawler mang lại nhiều hậu quả. Đầu tiên là mất kiểm soát hoàn toàn. Anh chị không thể biết dữ liệu nào đang bị thu thập, và chúng được sử dụng ra sao.
Một chuỗi phòng khám nha khoa 22 chi nhánh tại TP.HCM, với lượng khách hàng đông đảo và doanh thu ổn định, đã từng băn khoăn về vấn đề này. Họ có một kho tài liệu về các phương pháp điều trị, hình ảnh trước và sau khi làm răng, cùng các nghiên cứu nội bộ trên website. Nếu không khai báo, tất cả những dữ liệu này có thể bị AI sử dụng.ể đào tạo các mô hình y tế. Điều này tiềm ẩn rủi ro về đạo đức và pháp lý.
Hậu quả tiếp theo là khả năng bị phạt. Các quy định về bảo vệ dữ liệu cá nhân (như GDPR hay các luật tương tự ở Việt Nam) đang ngày càng chặt chẽ. Nếu website của anh chị vô tình để lộ thông tin cá nhân qua việc AI thu thập, doanh nghiệp có thể đối mặt với các án phạt nặng nề.
Cuối cùng, việc không khai báo còn ảnh hưởng đến hiệu suất SEO website. Khi AI crawler không biết đâu là nội dung quan trọng, đâu là nội dung cần bỏ qua, chúng có thể “lãng phí” tài nguyên quét. Điều này làm chậm quá trình lập chỉ mục và ảnh hưởng đến thứ hạng tìm kiếm tự nhiên của anh chị.
MONA nhấn mạnh rằng việc chủ động khai báo là bắt buộc. Chúng ta cần một chiến lược toàn diện để vừa tận dụng lợi ích của AI, vừa bảo vệ tài sản số của mình. Một trong những bước đầu tiên chính là hiểu và áp dụng đúng file LLMs.txt.


Nhiều anh chị chủ doanh nghiệp đang cảm thấy bối rối trước làn sóng AI, không biết cách nào để tận dụng công nghệ mới mà không bị cuốn vào những lời quảng cáo hào nhoáng. Chúng ta nhìn thấy tiềm năng nhưng lại lạc lối giữa những thuật ngữ phức tạp, không rõ đâu là giải pháp thực sự mang lại hiệu quả cho website của mình.
Sự thật là, việc các mô hình ngôn ngữ lớn (LLM) truy cập và tổng hợp thông tin từ website đang trở thành xu hướng tất yếu. Nếu không có hướng dẫn rõ ràng, AI có thể hiểu sai nội dung, bỏ qua những thông tin quan trọng hoặc thậm chí là khai thác dữ liệu mà anh chị không mong muốn. Điều này dẫn đến việc mất kiểm soát thương hiệu và lãng phí cơ hội tiếp cận khách hàng tiềm năng.
Tụi em tại MONA hiểu rõ nỗi lo này. Chúng ta cần một cách tiếp cận thực dụng, từng bước một, để biến những khái niệm công nghệ thành hành động cụ thể. Việc khai báo file LLMs.txt chính là một trong những bước đầu tiên, đơn giản nhưng cực kỳ quan trọng, giúp anh chị định hướng AI đúng cách.
MONA đã áp dụng cách làm này cho chính website của mình và cho nhiều đối tác. Chúng ta đã thấy rõ hiệu quả trong việc đảm bảo AI thu thập thông tin chính xác, đúng trọng tâm mà doanh nghiệp muốn truyền tải. Anh chị sẽ không còn phải băn khoăn về việc AI “đọc” website của mình như thế nào nữa.
Việc đầu tiên anh chị cần làm là tạo một file văn bản có tên chính xác là LLMs.txt. File này phải được đặt ở thư mục gốc (root directory) của website, tức là cùng cấp với file robots.txt quen thuộc.
Anh chị có thể hình dung, nếu website của một chuỗi nhà hàng F&B có 18 chi nhánh tại Hà Nội, doanh thu khoảng 45 tỷ/năm, muốn AI chỉ tập trung vào các món ăn mới ra mắt và chương trình khuyến mãi, chứ không phải các trang tuyển dụng cũ. Việc đặt file LLMs.txt đúng vị trí sẽ giúp AI tìm thấy hướng dẫn này ngay lập tức.
Tụi em khuyên anh chị nên dùng một trình soạn thảo văn bản đơn giản (như Notepad trên Windows hoặc TextEdit trên Mac) để tạo file này. Đảm bảo file không có định dạng phức tạp hay các ký tự đặc biệt không mong muốn. Sau đó, anh chị dùng FTP client (FileZilla, Cyberduck) hoặc thông qua giao diện quản lý file của hosting để tải file lên thư mục gốc.
Sau khi tạo file, anh chị cần viết các quy tắc cụ thể bên trong LLMs.txt để chỉ dẫn cho các AI crawler. Cú pháp tương tự như robots.txt, nhưng tập trung vào việc cho phép hoặc không cho phép LLM truy cập vào các phần nhất định của website.
Ví dụ, một chuỗi spa 28 chi nhánh tại HCM-HN-ĐN, doanh thu ~52 tỷ/tháng, thường có nhiều bài viết chia sẻ bí quyết làm đẹp, thông tin sản phẩm và cả các trang nội bộ quản lý lịch hẹn. Họ muốn AI học hỏi từ các bài viết về bí quyết, nhưng không muốn AI thu thập thông tin từ các trang quản lý khách hàng hay dữ liệu nội bộ.
Trong file LLMs.txt, anh chị sẽ dùng User-agent: để chỉ định AI crawler, và Allow: hoặc Disallow: để đặt quy tắc. Ví dụ:
User-agent: * (áp dụng cho tất cả AI crawler)Disallow: /admin/ (không cho phép truy cập thư mục admin)Disallow: /khach-hang/ (không cho phép truy cập thư mục khách hàng)Allow: /blog/ (cho phép truy cập thư mục blog, nơi có các bài viết chia sẻ)User-agent: Google-Extended (chỉ định riêng cho Google AI)Disallow: /gia-noi-bo/ (không cho phép Google AI truy cập trang giá nội bộ)MONA luôn nhấn mạnh tầm quan trọng của việc xác định rõ ràng mục tiêu của từng trang trước khi đặt quy tắc. Anh chị cần tự hỏi: “Thông tin nào tôi muốn AI tổng hợp để tạo ra giá trị cho khách hàng, và thông tin nào tôi muốn giữ kín để bảo vệ lợi thế cạnh tranh?”
Việc tạo và khai báo file LLMs.txt không phải là công việc một lần duy nhất. Website của anh chị luôn thay đổi, nội dung mới được thêm vào, và các mô hình AI cũng liên tục phát triển. Do đó, việc kiểm tra và cập nhật định kỳ là vô cùng cần thiết.
Một công ty logistics có 20 kho bãi và 500 xe tải, doanh thu hàng trăm tỷ/năm, thường xuyên cập nhật lộ trình, giá cước và các dịch vụ mới. Nếu file LLMs.txt không được cập nhật, AI có thể bỏ lỡ thông tin quan trọng về các tuyến đường mới, hoặc vẫn trích dẫn thông tin đã lỗi thời.
Tụi em khuyên anh chị nên rà soát file LLMs.txt ít nhất mỗi quý một lần, hoặc bất cứ khi nào có thay đổi lớn về cấu trúc website hay chiến lược nội dung. Hãy kiểm tra xem các quy tắc còn phù hợp không, có cần thêm hoặc bớt các đường dẫn nào không. Việc này đảm bảo AI luôn có được cái nhìn chính xác và mới nhất về doanh nghiệp của anh chị.
MONA đã chứng kiến nhiều doanh nghiệp nhỏ hơn, ví dụ một chuỗi cửa hàng tiện lợi 15 chi nhánh, doanh thu khoảng 30 tỷ/năm, gặp khó khăn khi AI trích dẫn các chương trình khuyến mãi đã hết hạn. Việc cập nhật LLMs.txt kịp thời đã giúp họ tránh được những hiểu lầm không đáng có với khách hàng.
Chúng ta cần một quy trình rõ ràng để không bỏ sót bước này, đảm bảo rằng chiến lược nội dung và định hướng AI luôn đồng bộ. Việc kiểm tra định kỳ cũng giúp anh chị phát hiện sớm bất kỳ vấn đề nào trong việc AI truy cập và xử lý dữ liệu từ website.

LLMs.txt giúp anh chị kiểm soát cách AI “đọc” website.Tính năng tương tự cũng áp dụng cho:


Nỗi lo mất kiểm soát dữ liệu, đặc biệt là nội dung độc quyền, đang trở thành gánh nặng cho nhiều doanh nghiệp khi AI crawler ngày càng quét sâu. Anh chị chủ doanh nghiệp luôn trăn trở làm sao để bảo vệ tài sản số của mình. Chúng ta hiểu rằng việc nội dung bị sao chép hay hiển thị sai lệch trên các nền tảng AI có thể gây thiệt hại lớn về thương hiệu và doanh thu.
Tụi em tại MONA đã trực tiếp chứng kiến và hỗ trợ một chuỗi spa cao cấp với 28 chi nhánh tại Thành phố Hồ Chí Minh, Hà Nội và Đà Nẵng, doanh thu trung bình khoảng 52 tỷ đồng mỗi tháng. Họ đối mặt với thách thức lớn khi nội dung về các liệu trình độc quyền, hình ảnh before-after, và bí quyết chăm sóc khách hàng liên tục bị AI tổng hợp, đôi khi còn xuất hiện trên các trang đối thủ mà không rõ nguồn gốc. Điều này làm giảm đáng kể lợi thế cạnh tranh của chuỗi spa.
MONA đã triển khai một giải pháp, trong đó có việc sử dụng file LLMs.txt kết hợp với các mô-đun tự động hoá khác. Việc này giúp chuỗi spa không chỉ bảo vệ được nội dung quý giá mà còn tối ưu hóa cách thương hiệu hiển thị trên các công cụ tìm kiếm AI, đảm bảo mọi thông tin khách hàng nhận được đều chính xác và có lợi cho doanh nghiệp.
Nội dung là tài sản vô giá của mọi doanh nghiệp, đặc biệt với các chuỗi dịch vụ như spa. Tụi em nhận thấy anh chị chủ doanh nghiệp thường xuyên lo lắng về việc các công thức liệu trình, hình ảnh độc quyền, hay bài viết chuyên sâu bị AI quét và tái tạo, đôi khi còn gán cho nguồn khác. Điều này làm mất đi sự khác biệt và công sức đầu tư của doanh nghiệp.
Với chuỗi spa 28 chi nhánh, họ có hàng ngàn bài viết mô tả liệu trình, video hướng dẫn chăm sóc da, và đặc biệt là bộ ảnh trước và sau khi sử dụng dịch vụ. Đây là tài sản được đầu tư rất lớn về thời gian và chi phí. MONA đã tư vấn triển khai file LLMs.txt để chỉ định rõ ràng những phần nội dung nào trên website không được phép dùng để huấn luyện các mô hình AI tổng quát. Chúng ta đã định nghĩa các thư mục chứa ảnh độc quyền, các trang mô tả liệu trình chuyên sâu là khu vực cấm đối với hầu hết các AI crawler.
Bên cạnh đó, tụi em còn tích hợp mô-đun giám sát nội dung tự động vào hệ thống quản lý website của chuỗi spa. Mô-đun này liên tục quét và so sánh nội dung trên các nền tảng công khai, sử dụng AI để phát hiện các trường hợp sao chép hoặc tổng hợp nội dung sai lệch từ website gốc. Khi có dấu hiệu vi phạm, hệ thống sẽ tự động gửi cảnh báo đến đội ngũ marketing của spa, giúp họ có hành động kịp thời để bảo vệ tài sản số của mình. MONA tin rằng, chủ động bảo vệ là cách phù hợp để giữ vững giá trị thương hiệu.
Việc hiển thị sai lệch thông tin thương hiệu trên các kết quả tìm kiếm do AI tổng hợp là nỗi ám ảnh của nhiều CEO. Anh chị luôn mong muốn khách hàng tiềm năng nhận được thông tin chính xác, nhất quán về dịch vụ và giá trị cốt lõi của mình. Một thông tin sai có thể dẫn đến mất niềm tin và bỏ lỡ cơ hội kinh doanh.
Trong trường hợp chuỗi spa, tụi em đã cấu hình file LLMs.txt không chỉ để chặn mà còn để hướng dẫn các AI crawler. Chúng ta đã chỉ định rõ ràng những phần nội dung quan trọng, những trang dịch vụ chủ lực cần được ưu tiên hiển thị và tổng hợp. Ví dụ, các trang giới thiệu liệu trình mới, chương trình khuyến mãi, hoặc thông tin liên hệ chính thức của từng chi nhánh đều được đánh dấu để AI hiểu và trích xuất một cách chính xác nhất.
MONA còn tích hợp hệ thống quản lý nội dung (CMS) tùy chỉnh, cho phép đội ngũ marketing của spa dễ dàng cập nhật và kiểm soát các meta-data, schema markup. Những yếu tố này cung cấp ngữ cảnh rõ ràng cho AI, giúp các mô hình ngôn ngữ lớn (LLM) hiểu sâu hơn về dịch vụ, đối tượng khách hàng, và lợi thế cạnh tranh của chuỗi. Kết quả là, khi khách hàng tìm kiếm các dịch vụ spa trên các nền tảng AI, thông tin về chuỗi spa này luôn được hiển thị một cách nổi bật, chính xác và hấp dẫn, giúp tăng cường khả năng tiếp cận và chuyển đổi khách hàng.
việc giữ vững lợi thế độc quyền là yếu tố sống còn. Chúng ta hiểu rằng anh chị chủ doanh nghiệp cần mọi công cụ để bảo vệ những gì đã xây dựng và phát triển. Việc để đối thủ dễ dàng sao chép ý tưởng hoặc nội dung là một rủi ro lớn.
Đối với chuỗi spa, việc bảo vệ các liệu trình độc quyền và bí quyết chăm sóc khách hàng là chìa khóa để giữ chân khách hàng trung thành và thu hút khách hàng mới. MONA đã giúp họ thiết lập một “hàng rào” kỹ thuật số thông qua LLMs.txt và các mô-đun bảo mật nội dung. Điều này đảm bảo rằng các AI crawler không thể dễ dàng “học” và tái tạo lại những giá trị cốt lõi làm nên tên tuổi của chuỗi spa.
Hơn nữa, việc kiểm soát cách AI tổng hợp và hiển thị thông tin còn giúp chuỗi spa định vị thương hiệu một cách chiến lược. Tụi em đã hỗ trợ họ trong việc xây dựng một “giọng thương hiệu” nhất quán trên mọi kênh số, bao gồm cả các phản hồi được tạo bởi AI. Điều này tạo ra một hình ảnh chuyên nghiệp, đáng tin cậy và độc đáo. MONA tin rằng, bằng cách kiểm soát chặt chẽ dữ liệu trên môi trường AI, doanh nghiệp sẽ không chỉ bảo vệ được mình mà còn tạo ra những cơ hội mới để phát triển và dẫn đầu thị trường.
Tính năng tương tự cũng áp dụng cho các ngành:


Nhiều anh chị chủ doanh nghiệp đang trăn trở về việc AI sẽ định hình lại thị trường. Ai cũng lo ngại mình sẽ bị bỏ lại phía sau nếu không nhanh chóng thích nghi. Sự bùng nổ của các mô hình ngôn ngữ lớn (LLM) mang đến cơ hội lớn, nhưng cũng tiềm ẩn rủi ro về việc dữ liệu độc quyền bị khai thác sai mục đích.
Chúng ta cần chủ động kiểm soát cách các AI crawler thu thập và sử dụng thông tin từ website của mình. Việc này giúp bảo vệ tài sản số, đồng thời định hình lợi thế cạnh tranh trong giai đoạn mới. Tụi em tại MONA nhận thấy đây là lúc anh chị cần một chiến lược rõ ràng, không thể chần chừ.
Đối với ngành thương mại điện tử, danh mục sản phẩm và các đánh giá từ khách hàng là tài sản vô giá. Anh chị đã đầu tư rất nhiều để xây dựng nội dung chi tiết, hình ảnh sản phẩm chất lượng và thu thập phản hồi chân thực. Việc này giúp xây dựng niềm tin và quyết định mua hàng.
Nếu không có biện pháp kiểm soát, các AI crawler có thể dễ dàng thu thập toàn bộ dữ liệu này. Đối thủ có thể dùng AI để phân tích xu hướng, thậm chí sao chép mô tả sản phẩm, làm giảm giá trị độc quyền của thương hiệu anh chị. Một chuỗi cửa hàng thời trang với 35 chi nhánh và doanh thu 40 tỷ/tháng từng chia sẻ nỗi lo này. Họ sợ các mẫu thiết kế mới, các bộ sưu tập theo mùa bị “học” quá nhanh.
Tụi em khuyên anh chị nên dùng file LLMs.txt để chỉ định rõ những phần nào của website được phép quét, phần nào cần bảo vệ. Các đánh giá khách hàng, thông tin khuyến mãi độc quyền, hoặc các mẫu sản phẩm chưa ra mắt có thể được chặn. MONA đã hỗ trợ nhiều doanh nghiệp thiết kế website bán hàng tích hợp sẵn các lớp bảo vệ dữ liệu này.
Trong ngành bất động sản, thông tin về các dự án, mô tả chi tiết căn hộ, và hình ảnh độc quyền là yếu tố then chốt để thu hút khách hàng. Mỗi dự án là một khoản đầu tư lớn về thời gian và nguồn lực để tạo ra nội dung hấp dẫn, chính xác.
Việc để AI crawler tự do quét có thể dẫn đến rủi ro thông tin bị sao chép, diễn giải sai lệch hoặc bị đối thủ sử dụng.ể tạo nội dung cạnh tranh. Một công ty phát triển dự án với hơn 200 nhân sự và 15 dự án lớn tại TP.HCM, doanh thu trên 80 tỷ/tháng, đã từng đối mặt với việc các mô tả dự án độc quyền của họ xuất hiện ở nhiều nơi trên mạng, gây khó khăn trong việc quản lý thương hiệu và thông tin chính thống.
Chúng ta cần một chiến lược kiểm soát chặt chẽ. Anh chị có thể sử dụng LLMs.txt để chặn các mô tả chi tiết về tiện ích nội khu, mặt bằng độc quyền hoặc các bài phân tích thị trường nội bộ. MONA cung cấp giải pháp phần mềm quản lý bất động sản, tích hợp các công cụ giúp bảo vệ tài sản số của anh chị, đảm bảo chỉ những thông tin mong muốn mới được AI tiếp cận.
Ngành giáo dục phụ thuộc rất nhiều vào chất lượng giáo trình và tài liệu giảng dạy. Đây là thành quả của quá trình nghiên cứu, biên soạn công phu của đội ngũ chuyên gia. Giá trị cốt lõi của một trung tâm nằm ở nội dung độc quyền và phương pháp truyền đạt.
Nếu không kiểm soát, các mô hình AI có thể dễ dàng học hỏi, tổng hợp và tái tạo lại các nội dung này. Điều này làm giảm lợi thế cạnh tranh của anh chị, thậm chí ảnh hưởng đến doanh thu khi nội dung bị “pha loãng” trên internet. Một hệ thống giáo dục trực tuyến với 40.000 học viên và 760 giảng viên chuyên nghiệp (như Khanh Hung Academy) luôn ưu tiên bảo vệ tài liệu giảng dạy độc quyền của mình.
MONA khuyến nghị anh chị dùng LLMs.txt để bảo vệ các khóa học, giáo trình, bài kiểm tra mẫu chưa công bố. Tụi em đã triển khai hệ thống quản lý học tập (LMS) và phần mềm E-learning cho nhiều đối tác. Các giải pháp này tích hợp cơ chế bảo vệ nội dung, giúp anh chị yên tâm phát triển mà không lo bị sao chép.
Trong ngành nhà hàng, khách sạn, thông tin về thực đơn, giá cả, các gói dịch vụ và chương trình khuyến mãi cần được truyền tải chính xác. Mỗi món ăn, mỗi dịch vụ đều được đầu tư về hình ảnh và mô tả để tạo sức hút.
Việc thông tin bị AI thu thập và diễn giải sai lệch có thể gây hiểu lầm cho khách hàng, ảnh hưởng đến uy tín thương hiệu. Một chuỗi nhà hàng 28 chi nhánh tại HCM-HN-ĐN, doanh thu khoảng 52 tỷ/tháng, luôn chú trọng đến việc hiển thị thông tin chính xác trên các nền tảng số. Họ sợ AI tổng hợp sai giá hoặc sai thành phần món ăn.
Anh chị có thể dùng LLMs.txt để kiểm soát việc AI quét các thông tin nhạy cảm về giá, công thức độc quyền, hoặc các chương trình khuyến mãi chỉ áp dụng trong thời gian giới hạn. Tụi em đã xây dựng phần mềm quản lý nhà hàng và phần mềm quản lý spa tích hợp khả năng kiểm soát dữ liệu. Điều này giúp anh chị duy trì sự nhất quán và chính xác của thông tin trên mọi kênh.


Nhiều anh chị chủ doanh nghiệp đang đối mặt với một thực tế: chi phí cơ hội (COI) khi không kiểm soát dữ liệu AI ngày càng lớn. Chúng ta đầu tư vào website, nội dung, rồi bỏ mặc cho các công cụ AI tự do quét, tự do hiểu. Việc này tiềm ẩn rủi ro lớn. Dữ liệu quý giá có thể bị hiểu sai, bị bỏ qua, hoặc thậm chí bị dùng để đào tạo AI của đối thủ. Đây là một khoản lỗ thầm lặng nhưng rất đáng kể, ảnh hưởng trực tiếp đến hiệu suất đầu tư marketing và SEO của doanh nghiệp.
MONA hiểu rằng anh chị luôn muốn mọi tài nguyên số đều được tối ưu. Đặc biệt, với sự phát triển của các mô hình ngôn ngữ lớn (LLM) như Claude hay ChatGPT, việc định hướng cách chúng đọc và hiểu website là điều không thể bỏ qua. Chúng ta cần một chiến lược rõ ràng để đảm bảo AI phục vụ mục tiêu kinh doanh, thay vì chỉ là một công cụ thu thập thông tin ngẫu nhiên.
Tụi em đã chứng kiến nhiều doanh nghiệp chi hàng chục tỷ đồng mỗi năm cho marketing và nội dung. Tuy nhiên, khi AI bắt đầu trở thành kênh tìm kiếm chính, các website này lại không được chuẩn bị. Kết quả là, thông tin sản phẩm, dịch vụ bị AI diễn giải sai lệch, khách hàng tiềm năng không tìm thấy đúng nội dung, và doanh số bị ảnh hưởng đáng kể. Đây chính là COI khi anh chị không chủ động tối ưu website cho kỷ nguyên AI.
Anh chị đã bỏ công sức và tiền bạc xây dựng hàng nghìn trang sản phẩm, bài viết blog, và tài liệu hỗ trợ trên website. Mỗi từ, mỗi hình ảnh đều chứa đựng giá trị thương hiệu và thông tin kinh doanh cốt lõi. Tuy nhiên, nếu không có cơ chế rõ ràng như `LLMs.txt`, các AI crawler có thể bỏ qua những phần quan trọng, hoặc tệ hơn, hiểu sai ngữ cảnh của nội dung.
Một chuỗi nhà hàng cao cấp với 18 chi nhánh tại Hà Nội và Đà Nẵng, doanh thu trung bình 40 tỷ/tháng, đã từng gặp tình huống này. Họ đầu tư rất lớn vào mô tả món ăn, câu chuyện thương hiệu và các chương trình khuyến mãi độc quyền trên website. Nhưng khi khách hàng tìm kiếm qua các công cụ AI, thông tin lại bị lẫn lộn với các đối thủ, hoặc AI chỉ trích dẫn những đoạn chung chung, không làm nổi bật được giá trị khác biệt của chuỗi. Lý do là website chưa được “dạy” cách giao tiếp hiệu quả với LLM.
Tụi em thường khuyên các chủ doanh nghiệp nên xem website như một kho tri thức sống. Nếu không có người hướng dẫn, kho tri thức đó sẽ rất khó được khai thác triệt để. Việc khai báo `LLMs.txt` chính là cách anh chị đặt ra các nguyên tắc, chỉ dẫn cho AI, giúp chúng tập trung vào những thông tin quan trọng nhất, hiểu đúng ý nghĩa và ngữ cảnh mà anh chị muốn truyền tải.
Điều này không chỉ giúp AI hiển thị thông tin chính xác hơn mà còn bảo vệ tài sản trí tuệ của anh chị. Chúng ta không muốn nội dung độc quyền bị AI sử dụng sai mục đích, hoặc bị “học” một cách vô tội vạ mà không mang lại lợi ích trực tiếp cho doanh nghiệp. Việc kiểm soát dữ liệu là bước đầu tiên để biến AI thành đồng minh, không phải là một thực thể vô chủ trên không gian mạng.
MONA không chỉ cung cấp giải pháp khai báo `LLMs.txt` đơn thuần. Tụi em mang đến một chiến lược toàn diện để tối ưu hóa website cho kỷ nguyên AI, kết hợp với các giải pháp phần mềm tự động hóa sản xuất (production-grade) mà MONA đã phát triển. Chúng ta cùng nhau xây dựng một nền tảng số không chỉ thân thiện với người dùng mà còn thông minh với AI.
MONA đã giúp một doanh nghiệp bán lẻ thời trang với 25 cửa hàng trên toàn quốc, doanh thu hơn 55 tỷ/năm, tái cấu trúc toàn bộ website và chiến lược nội dung. Bằng cách triển khai `LLMs.txt` và tích hợp các mô-đun phần mềm như MONA eCommerce, tụi em đã giúp AI hiểu rõ hơn về từng bộ sưu tập, chương trình giảm giá, và chính sách khách hàng. Kết quả là, các truy vấn của khách hàng qua AI đều nhận được câu trả lời chính xác, dẫn đến tăng tỷ lệ chuyển đổi và giảm tải cho đội ngũ chăm sóc khách hàng.
Với MONA, AI không phải là một công cụ riêng lẻ, mà là một lớp phủ thông minh xuyên suốt từ thiết kế website, chiến lược SEO đến vận hành. Tụi em giúp anh chị không chỉ khai báo `LLMs.txt` đúng chuẩn mà còn tích hợp các phần mềm quản lý chuyên biệt, đảm bảo mọi dữ liệu được thu thập, xử lý và trình bày một cách tối ưu nhất cho cả con người và máy móc. Đây là cách MONA giúp anh chị giảm thiểu COI và tối đa hóa hiệu suất đầu tư vào công nghệ.
Để bắt đầu xây dựng một nền tảng số vững chắc, nơi dữ liệu của anh chị được bảo vệ và khai thác hiệu quả bởi AI, tụi em mời anh chị liên hệ MONA. Đội ngũ chuyên gia của tụi em sẽ tư vấn giải pháp phù hợp nhất, giúp doanh nghiệp anh chị không chỉ thích nghi mà còn vươn lên mạnh mẽ trong kỷ nguyên tự động hóa.
Tính năng tương tự cũng áp dụng cho các ngành:



Founder Phần mềm MONA AI
Người đứng sau các sản phẩm phần mềm AI của MONA, đồng thời phụ trách mảng SEO tổng thể giúp hàng nghìn website lên top bền vững. Nhân trực tiếp nghiên cứu cách Google và các công cụ AI như ChatGPT, Gemini đọc – xếp hạng nội dung, rồi biến thành quy trình SEO đo được cho doanh nghiệp.




Dịch vụ thiết kế
website chuyên nghiệp
Sở hữu website với giao diện đẹp, độc quyền 100%, bảo hành trọn đời với khả năng
mở rộng tính năng linh hoạt theo sự phát triển doanh nghiệp ngay hôm nay!






