











 VI
VI
 EN
EN


















Nhắn tin qua
Zalo Official

 Dịch vụ
Bạn đang Kinh doanh dịch vụ
Dịch vụ
Bạn đang Kinh doanh dịch vụ








02 Tháng Bảy, 2024

MONA Creator
Trong SEO, hiểu rõ “crawl là gì” và nguyên tắc hoạt động của crawl website rất quan trọng cho việc tối ưu hóa nội dung, cải thiện thứ hạng trang web trên kết quả tìm kiếm. Bạn có thể đảm bảo rằng thông tin quan trọng của trang web được công cụ tìm kiếm nhận diện và hiển thị đúng cách chỉ với khái niệm này. Bài viết ngày hôm nay của MONA Media sẽ cung cấp cái nhìn sâu sắc về crawl là gì và cách hoạt động của nó trong SEO, giúp bạn nắm bắt cơ hội để nâng cao hiệu suất trang web của mình, đừng bỏ qua nhé.
Hiểu rõ về crawl dữ liệu là bước đầu tiên để tối ưu hóa trang web và cải thiện thứ hạng trên công cụ tìm kiếm. Cùng MONA đi qua hai khái niệm cơ bản này ngay dưới đây nhé.

Crawl là gì? Crawl data là gì? là những thắc mắc mà các SEO-er thường gặp khi mới tập tành bắt đầu làm SEO và quản lý website.
Hiểu một cách đơn giản thì Crawl là quá trình thu thập và quét dữ liệu trên các trang web bằng các bot (hay còn được gọi là spider) của công cụ tìm kiếm. Mục tiêu của việc crawl là thu thập thông tin về cấu trúc và nội dung trang web, từ đó lập chỉ mục và xếp hạng trên kết quả tìm kiếm. Dữ liệu có thể bao gồm văn bản, hình ảnh, video, PDF, và nhiều định dạng khác. Hiểu rõ “Crawl data là gì và cách ứng dụng” sẽ giúp bạn tối ưu hóa trang web để cải thiện khả năng hiển thị và hiệu quả SEO.
Crawler là các chương trình tự động được thiết kế để duyệt qua các trang web và thu thập dữ liệu. Các công cụ tìm kiếm lớn như Google sử dụng web crawler để crawl dữ liệu và lập chỉ mục nội dung web, giúp cải thiện kết quả tìm kiếm.
Ứng dụng của web crawler không chỉ dừng lại ở việc SEO trang web lên top mà còn mở rộng đến việc thu thập dữ liệu có cấu trúc, giám sát thay đổi trên web, và hỗ trợ phân tích thị trường. Hiểu rõ crawl là gì giúp nâng cao hiệu quả SEO và quản lý website chuyên nghiệp hơn.
-> Có thể bạn muốn tham khảo thêm: Web Scraping là gì? Cách hoạt động và ứng dụng Web Scraping hiệu quả

Crawl dữ liệu đóng vai trò cực kỳ quan trọng trong việc tìm kiếm thông tin trên mạng, thể hiện rõ ràng qua 3 ý dưới đây:
Không chỉ giúp tối ưu hóa kết quả tìm kiếm, crawl dữ liệu còn mang lại nhiều lợi ích quan trọng khác với mục đích cuối cùng là giúp người dùng tiết kiệm thời gian, công sức và đạt được kết quả tìm kiếm chuẩn xác, phù hợp nhất.
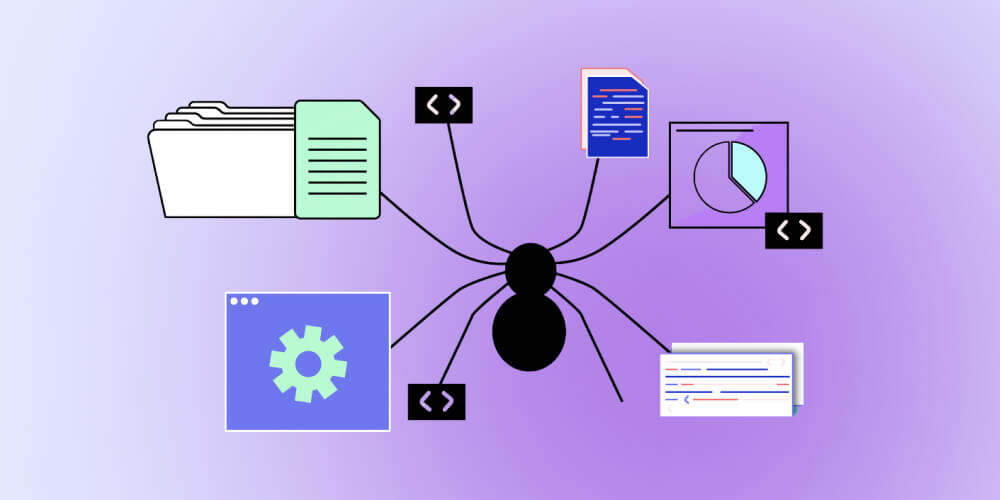
Bot công cụ tìm kiếm hoạt động dựa trên việc thu thập và lập chỉ mục thông tin trong việc crawl dữ liệu website. Quá trình hoạt động của bot khá đơn giản, bắt đầu bằng việc:
Lúc này, các bot sẽ ưu tiên các trang web dựa trên một số yếu tố như: lượng backlink, traffic và tầm quan trọng của nội dung,… Những trang web có thông số cao thường được coi là cung cấp thông tin chất lượng và có thẩm quyền, do đó được ưu tiên crawl data trước.
Bên cạnh đó, bot công cụ tìm kiếm cũng tuân theo một số chính sách về tần suất và thứ tự thu thập dữ liệu, giúp đảm bảo rằng các trang quan trọng và có cập nhật mới được crawl dữ liệu thường xuyên hơn. Qua đó giúp cải thiện khả năng cung cấp kết quả tìm kiếm chính xác và kịp thời cho người dùng.
Muốn ngăn Google Crawling những dữ liệu bạn không muốn trên website? Cùng MONA tìm hiểu 3 cách phổ biến để bạn cải thiện hiệu quả SEO của trang web thông qua việc ngăn Google Crawling những thông tin không muốn nhé.

Tệp Robots.txt được đặt tại thư mục gốc của trang web, chứa các chỉ thị cho các bot công cụ tìm kiếm về những phần nào trên trang web nên hoặc không nên thu thập dữ liệu. Điều này giúp bạn bảo vệ các thông tin nhạy cảm và tối ưu hóa hiệu suất crawl data.
Robots.txt cũng cho phép bạn kiểm soát tốc độ thu thập dữ liệu, giúp giảm tải cho server và cải thiện hiệu suất trang web. Khi Googlebot phát hiện tệp Robots.txt, nó sẽ tuân theo các chỉ thị để crawl dữ liệu một cách hợp lý. Điều này đảm bảo rằng các trang quan trọng được lập chỉ mục và xếp hạng tốt trên kết quả tìm kiếm.
Crawl Budget là khái niệm chỉ số lượng URL mà Googlebot có thể thu thập trước khi dừng lại. Để tối ưu hóa quá trình này, bạn cần lưu ý những điểm sau:

Tham số URL là các đoạn mã thêm vào URL chính để phân biệt các phiên bản khác nhau của cùng một nội dung trang web.
Ví dụ, khi bạn đang mua sắm trên shopee, bạn có thể sử dụng các tham số để lọc sản phẩm theo giá, màu sắc, kích cỡ tùy theo sở thích của bạn. Tính năng thông số URL trong Google Search Console cũng như vậy! Tính năng này cho phép bạn chỉ định cho Googlebot biết cách xử lý các tham số này, lập chỉ mục hoặc bỏ qua. Điều này giúp ngăn chặn Googlebot crawl dữ liệu các trang trùng lặp và giữ cho chỉ mục của bạn sạch sẽ và hiệu quả.

Crawl dữ liệu không phải một quá trình ngẫu nhiên mà bị chi phối bởi nhiều yếu tố khác. Dưới đây là những yếu tố mà MONA nghĩ bạn cần chú ý để “hợp tác” với Googlebot một cách hiệu quả hơn:
Và tất nhiên, để có thể crawl dữ liệu một cách hiệu quả thì các công cụ là một phần không thể thiếu. Hãy cùng MONA tìm hiểu về bot crwal của các công cụ tìm kiếm phổ biến hiện nay, nhằm giúp bạn tối ưu hóa quá trình SEO của mình nhanh chóng hơn.

Googlebot là một phần mềm robot do Google phát triển và được biết đến như một công cụ quan trọng trong việc crawl dữ liệu. Googlebot giúp đảm bảo rằng các trang web được cập nhật đầy đủ và hiển thị trên các kết quả tìm kiếm của Google. Bạn có thể tận dụng con bot này để cải thiện chiến dịch SEO của mình bằng cách:
-> Khám phá ngay: Hướng dẫn từ A-Z cách submit URL lên google nhanh nhất
Bingbot trong crawl là gì? Bingbot là một thành phần quan trọng trong hệ thống tìm kiếm của Bing, chịu trách nhiệm thu thập và cập nhật dữ liệu từ các trang web trên Internet để cung cấp kết quả tìm kiếm chính xác và đáng tin cậy cho người dùng. Các hoạt động chính của Bingbot bao gồm:

Yandexbot là một thành phần quan trọng trong hệ thống tìm kiếm của Yandex. Vậy công việc chính của Yandexbot trong crawl là gì? Nhiệm vụ của Yandexbot cũng tương tự Bingbot, Googlebot bao gồm:
Hiểu rõ về “crawl là gì” hay “crawling là gì?” sẽ giúp bạn đảm bảo website dễ dàng được crawl và index, từ đó cải thiện vị trí của trang web trên kết quả tìm kiếm và nâng cao hiệu suất kinh doanh của doanh nghiệp. Đồng thời, nắm vững các nguyên tắc hoạt động của crawl website còn giúp bạn xây dựng chiến lược SEO thông minh và hiệu quả hơn. Nếu bạn muốn tạo ra sự khác biệt trong cuộc đua trực tuyến và vươn lên dẫn đầu trên Google, hãy liên hệ với MONA để được tư vấn giải pháp phù hợp và nhận báo giá SEO website phù hợp nhất cho nhu cầu SEO của bạn.
MONA Creator




Dịch vụ thiết kế
website chuyên nghiệp
Sở hữu website với giao diện đẹp, độc quyền 100%, bảo hành trọn đời với khả năng
mở rộng tính năng linh hoạt theo sự phát triển doanh nghiệp ngay hôm nay!



NHẬN TƯ VẤN SEO MIỄN PHÍ !





