



 VI
VI
 EN
EN















Nhắn tin qua
Zalo Official

 Sản phẩmSản phẩm
Sản phẩmSản phẩm Gấu CườiTrả lời khách 24/7 trên web, Fanpage, Zalo và tự thu lead về cho sale.
Gấu CườiTrả lời khách 24/7 trên web, Fanpage, Zalo và tự thu lead về cho sale.
 Gấu TeleSalesGọi điện tư vấn, chăm khách như tổng đài viên thật, không sót cuộc nào.
Gấu TeleSalesGọi điện tư vấn, chăm khách như tổng đài viên thật, không sót cuộc nào.
 Dê CườiTư vấn và chốt đơn cho shop bán lẻ, thương mại điện tử ngay trong khung chat.
Dê CườiTư vấn và chốt đơn cho shop bán lẻ, thương mại điện tử ngay trong khung chat.
 Gấu WebmasterNhắn nhóm Zalo là web sửa xong, tự rà lỗi mỗi tuần, báo cáo sếp cuối tháng.
Gấu WebmasterNhắn nhóm Zalo là web sửa xong, tự rà lỗi mỗi tuần, báo cáo sếp cuối tháng.
 Gấu Pháp ChếSoạn hợp đồng và rà soát điều khoản pháp lý chỉ trong vài phút.
Gấu Pháp ChếSoạn hợp đồng và rà soát điều khoản pháp lý chỉ trong vài phút.
 Gấu Báo GiáTự lên báo giá đúng mẫu và gửi khách ngay khi có yêu cầu.
Gấu Báo GiáTự lên báo giá đúng mẫu và gửi khách ngay khi có yêu cầu.
 AI chăm sóc khách hàngHỗ trợ phòng kinh doanh theo dõi và giữ chân khách hàng cũ.
AI chăm sóc khách hàngHỗ trợ phòng kinh doanh theo dõi và giữ chân khách hàng cũ.
 Gấu Tuyển DụngLọc hồ sơ, hẹn lịch và phỏng vấn ứng viên tự động cho phòng nhân sự.
Gấu Tuyển DụngLọc hồ sơ, hẹn lịch và phỏng vấn ứng viên tự động cho phòng nhân sự.  Thiết kế website PremiumVừa đẹp vừa thuyết phục được khách.
Thiết kế website PremiumVừa đẹp vừa thuyết phục được khách.
 Thiết kế Website AI MớiWeb đẹp có hồn, biết tự bán 24/7.
Thiết kế Website AI MớiWeb đẹp có hồn, biết tự bán 24/7.
 Dịch vụ SEO Tối ưu chi phíHút traffic từ khách có nhu cầu sẵn.
Dịch vụ SEO Tối ưu chi phíHút traffic từ khách có nhu cầu sẵn.
 Quay video doanh nghiệpNâng tầm uy tín bằng video chất lượng.
Quay video doanh nghiệpNâng tầm uy tín bằng video chất lượng.
 Dịch vụ dựng video AI MớiDựng phim câu chuyện công ty bằng AI.
Dịch vụ dựng video AI MớiDựng phim câu chuyện công ty bằng AI.
 MONA SkillHubPhần mềm đào tạo nội bộ doanh nghiệp.
MONA SkillHubPhần mềm đào tạo nội bộ doanh nghiệp.
 Hệ thống NHTQTrọn nghiệp vụ vận chuyển Trung – Việt.
Hệ thống NHTQTrọn nghiệp vụ vận chuyển Trung – Việt.
 MONA JMSPhần mềm tiệm vàng, kim cương, cầm đồ.
Gấu Cười MONA ĐANG TỰ XÀITrả lời khách 24/7 trên website, Zalo OA, Messenger và thu lead về cho sale.
Dê CườiChốt đơn bán lẻ và sàn: Shopee, TikTok Shop, web. Chăm cả khách sỉ, đại lý.
Gấu WebmasterCập nhật nội dung, tối ưu SEO website mỗi ngày.
Gấu TeleSalesGọi điện tư vấn, chăm khách như tổng đài viên thật.
Gấu Tuyển DụngLọc hồ sơ, hẹn lịch, phỏng vấn ứng viên tự động.
AI chăm sóc khách hàngGiữ khách cũ, cứu lead đã rớt cho phòng kinh doanh.
Gấu Pháp ChếSoạn hợp đồng, rà điều khoản trong vài phút.
Gấu Báo GiáLên báo giá đúng mẫu, gửi khách ngay khi có yêu cầu.
MONA JMSPhần mềm tiệm vàng, kim cương, cầm đồ.
Gấu Cười MONA ĐANG TỰ XÀITrả lời khách 24/7 trên website, Zalo OA, Messenger và thu lead về cho sale.
Dê CườiChốt đơn bán lẻ và sàn: Shopee, TikTok Shop, web. Chăm cả khách sỉ, đại lý.
Gấu WebmasterCập nhật nội dung, tối ưu SEO website mỗi ngày.
Gấu TeleSalesGọi điện tư vấn, chăm khách như tổng đài viên thật.
Gấu Tuyển DụngLọc hồ sơ, hẹn lịch, phỏng vấn ứng viên tự động.
AI chăm sóc khách hàngGiữ khách cũ, cứu lead đã rớt cho phòng kinh doanh.
Gấu Pháp ChếSoạn hợp đồng, rà điều khoản trong vài phút.
Gấu Báo GiáLên báo giá đúng mẫu, gửi khách ngay khi có yêu cầu.
 Chuyển đổi AI toàn phầnGiải pháp tổng cho doanh nghiệp, 3 lớp triển khai.
Chuyển đổi AI toàn phầnGiải pháp tổng cho doanh nghiệp, 3 lớp triển khai.
 Viết AI Agent theo yêu cầuĐặt riêng một con AI gánh đúng nghiệp vụ của bạn.
Viết AI Agent theo yêu cầuĐặt riêng một con AI gánh đúng nghiệp vụ của bạn.
 Phần mềm theo yêu cầuCRM, ERP, HRM tích hợp sẵn AI tự động hoá.
Phần mềm theo yêu cầuCRM, ERP, HRM tích hợp sẵn AI tự động hoá.
 SEO & AEO thời đại AIĐược Google lẫn AI trích dẫn, không chỉ xếp hạng.
SEO & AEO thời đại AIĐược Google lẫn AI trích dẫn, không chỉ xếp hạng.
 Kiến thức AI cho doanh nghiệpBài phân tích, hướng dẫn ứng dụng AI vào vận hành.
Kiến thức AI cho doanh nghiệpBài phân tích, hướng dẫn ứng dụng AI vào vận hành.
 Khoá học AI miễn phí
Khoá học AI miễn phí Công cụ AI trong công việc
Công cụ AI trong công việc18 Tháng 3, 2023

Bạn có bao giờ thắc mắc Google thu thập dữ liệu website của bạn như thế nào không? Tại sao chỉ sau vài giờ đăng bài, nội dung của bạn đã xuất hiện trên kết quả tìm kiếm? “Người đứng sau” toàn bộ quá trình đó được gọi là Googlebot. Vậy Googlebot là gì và làm sao để tối ưu website thân thiện với Googlebot? Cùng MONA Media tìm hiểu chi tiết trong bài này nhé.
Googlebot là công cụ thu thập dữ liệu (Web Crawler hoặc Spider) do Google phát triển, có nhiệm vụ đi khắp internet để quét nội dung từ các website. Từ văn bản, hình ảnh cho đến liên kết, tất cả sẽ được Googlebot thu thập và đưa vào chỉ mục (index) khổng lồ của Google. Nhờ vậy, khi người dùng tìm kiếm một từ khóa bất kỳ, Google có thể hiển thị những kết quả phù hợp và chính xác nhất.

Googlebot không chỉ có một dạng duy nhất. Google chia thành nhiều loại để mô phỏng hành vi người dùng trên các thiết bị và mục đích khác nhau, cụ thể như:
Googlebot Desktop: Mô phỏng cách người dùng truy cập website bằng máy tính hoặc laptop, giúp Google hiểu website hiển thị thế nào trên màn hình lớn.
Googlebot Smartphone: Mô phỏng trải nghiệm người dùng trên điện thoại di động. Đây là loại Googlebot được ưu tiên nhất hiện nay vì Google đang áp dụng Mobile-first Indexing (lập chỉ mục dựa trên phiên bản di động trước).
Ngoài ra còn có các biến thể chuyên biệt:
Googlebot Image: Thu thập dữ liệu từ hình ảnh, phục vụ tìm kiếm Google Hình ảnh.
Googlebot News: Quét nội dung từ báo, blog để hiển thị trên Google News.
Googlebot Video: Thu thập thông tin từ video, hỗ trợ kết quả tìm kiếm video.
Google StoreBot: Thu thập dữ liệu từ website thương mại điện tử hoặc ứng dụng trên Google Play
Hiện nay, phần lớn hoạt động lập chỉ mục được thực hiện bởi Googlebot Smartphone, vì Google ưu tiên phiên bản mobile của website. Điều đó có nghĩa là, nếu website của bạn không thân thiện với di động, khả năng hiển thị trên Google sẽ bị ảnh hưởng.
Để tối ưu SEO cho website hiệu quả, bạn cần hiểu rõ con bot thu thập dữ liệu của Google hoạt động như thế nào. Nói một cách dễ hiểu, Googlebot sẽ “đi dạo” khắp internet, tìm kiếm và thu thập dữ liệu từ nhiều trang web, rồi mang về lưu trữ trong hệ thống Google.

Quá trình này diễn ra qua 3 bước chính:
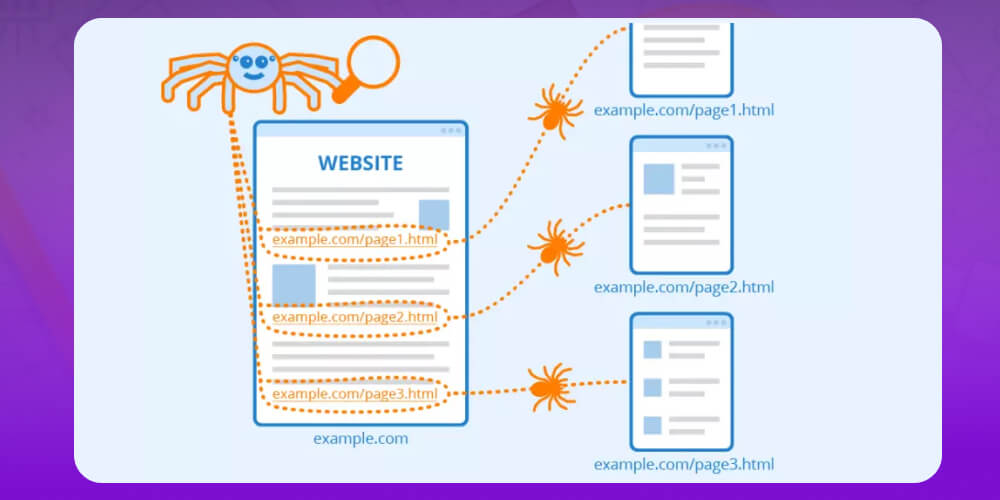
Crawling (Thu thập dữ liệu): Googlebot “đi dạo” trên internet, tìm các trang web mới thông qua backlink, sitemap hoặc URL được gửi lên Google Search Console. Sau đó, nó đọc mã HTML và nội dung để hiểu trang web nói về gì.
Processing & Rendering (Xử lý và hiển thị): Googlebot phân tích dữ liệu đã thu thập như văn bản, hình ảnh, video… và chuyển đổi thành dạng mà Google có thể hiểu được.
Indexing (Lập chỉ mục): Dữ liệu sau khi xử lý sẽ được đưa vào chỉ mục, kho lưu trữ khổng lồ của Google. Khi người dùng tìm kiếm, Google sẽ lấy thông tin từ kho này để hiển thị kết quả phù hợp.
-> Xem thêm: Cách để xếp hạng trên AI Overview của Google hiệu quả
Googlebot đóng vai trò cực kỳ quan trọng trong việc quyết định website của bạn có hiển thị trên Google hay không và đứng ở vị trí nào trên kết quả tìm kiếm.
Googlebot luôn chủ động tìm kiếm và thu thập dữ liệu từ các trang web, do đó, bạn không cần lo nó “bỏ quên” website của bạn. Vấn đề cần quan tâm là tốc độ thu thập dữ liệu của Googlebot tiếp cận nhanh hay chậm. Nếu bot có thể sớm phát hiện những nội dung mới, chỉnh sửa hoặc cập nhật trên website, thì trang của bạn sẽ được tái lập chỉ mục nhanh hơn, đồng nghĩa với việc tăng cơ hội cải thiện thứ hạng trên Google.
Ngược lại, nếu Googlebot bị hạn chế truy cập hoặc chỉ quét được một phần nhỏ nội dung, website sẽ bị đánh giá thấp. Google có thể xem đây là dấu hiệu “nội dung không được làm mới, không hữu ích”, khiến thứ hạng bị giảm đáng kể.
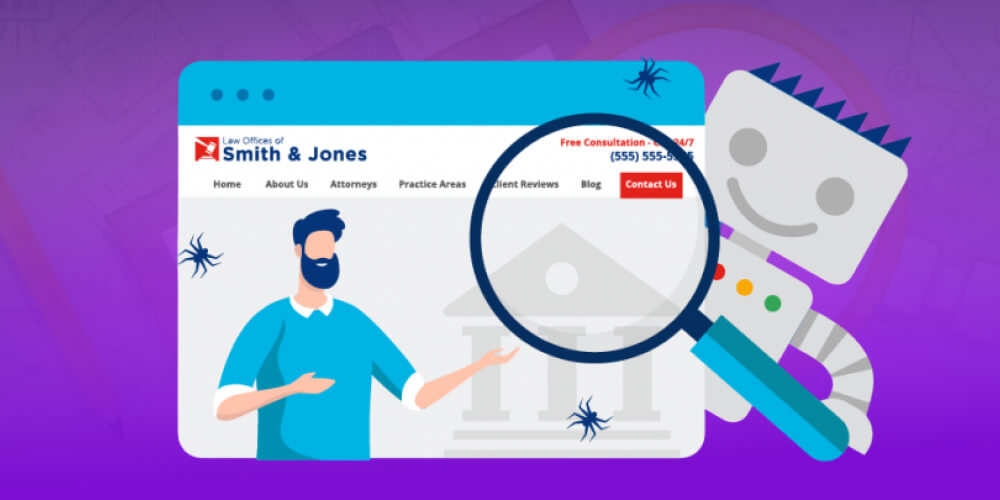
Vì vậy, để website hoạt động hiệu quả trên Google, bạn cần đảm bảo Googlebot có thể tiếp cận dễ dàng và thường xuyên. Hãy kiểm tra xem website của bạn có đang chặn bot hay gặp lỗi từ máy chủ (Firewall, DNS…) hay không, để tránh cản trở quá trình thu thập dữ liệu.
Mặc dù Googlebot là công cụ tự động giúp Google thu thập và lập chỉ mục nội dung của các website một cách liên tục, nhưng đôi khi bạn có thể nhận thấy quá trình này diễn ra sẽ chậm hơn so với trước đây. Tình trạng này không phải ngẫu nhiên, mà thường bắt nguồn từ những nguyên nhân cụ thể.
Dưới đây là những lý do phổ biến khiến Googlebot “bò” chậm trên website của bạn:
Nếu máy chủ phản hồi chậm hoặc website tải nhiều tài nguyên nặng, Googlebot sẽ mất nhiều thời gian để xử lý mỗi trang. Để tránh gây quá tải cho server, Google có thể tự động giảm tần suất và độ sâu của việc thu thập, dẫn đến việc lập chỉ mục bị chậm lại.

Các lỗi như 404, 500, redirect loop hay cấu trúc URL không ổn định khiến Googlebot phải tốn thêm thời gian xử lý. Điều này làm gián đoạn quá trình crawl và ảnh hưởng đến hiệu quả lập chỉ mục. Việc khắc phục các lỗi này là bước quan trọng để giúp Googlebot hoạt động trơn tru hơn.
Mỗi website đều có một “ngân sách crawl” nhất định. Nếu website có quá nhiều trang chất lượng thấp, nội dung trùng lặp hoặc trang rác, Googlebot sẽ dành thời gian vào những phần không quan trọng, làm giảm khả năng khám phá các trang giá trị cao.

Googlebot có thời gian chờ giới hạn cho mỗi trang. Nếu trang web tải quá lâu, bot có thể từ bỏ việc thu thập trước khi hoàn tất, dẫn đến việc bỏ sót nội dung hoặc chỉ thu thập được một phần.
Googlebot thường ưu tiên ghé thăm những website có tần suất cập nhật cao và được liên kết từ các nguồn uy tín. Nếu website của bạn ít được liên kết hoặc lâu ngày không có nội dung mới, Google có thể giảm tần suất crawl, coi trang của bạn là ít thay đổi hoặc ít quan trọng.
Những trang web dựa nhiều vào JavaScript, AJAX hoặc các công nghệ frontend hiện đại có thể gây khó khăn cho Googlebot trong việc render và hiểu nội dung. Quá trình này đòi hỏi thêm thời gian xử lý, làm chậm đáng kể tốc độ crawl và lập chỉ mục.
Googlebot thường thu thập dữ liệu của URL mới thông qua các liên kết trên những trang đã được quét trước đó. Vì vậy, không thể chắc chắn rằng Google sẽ bỏ qua một trang mới chỉ vì nó không có link công khai. Chỉ cần có một link dẫn ra ngoài, URL đó vẫn có thể bị Google phát hiện qua nhật ký liên kết giới thiệu (referral).
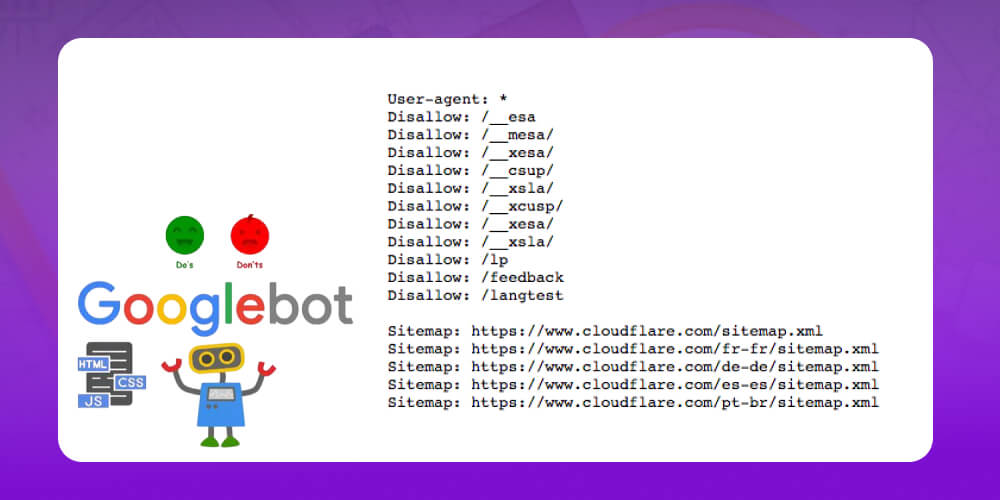
Nếu bạn muốn chặn Googlebot truy cập một số nội dung nhất định, có vài cách phổ biến như:
Ngăn Googlebot thu thập dữ liệu (crawl): Sử dụng tệp robots.txt để chặn bot không được phép truy cập vào một hoặc nhiều thư mục/trang trên website.
Ngăn Google lập chỉ mục (index): Nếu bạn không muốn nội dung xuất hiện trên Google Search, hãy dùng thẻ noindex trong HTML. Lúc này Google có thể biết URL tồn tại, nhưng sẽ không hiển thị nó trên kết quả tìm kiếm.
Ngăn cả Googlebot lẫn người dùng truy cập: Trường hợp bạn muốn giữ nội dung hoàn toàn riêng tư (ví dụ: trang quản trị, trang thử nghiệm), hãy dùng bảo mật bằng mật khẩu hoặc các phương pháp chặn truy cập khác.
Lưu ý: Việc chặn Googlebot không chỉ ảnh hưởng đến kết quả tìm kiếm Google (SERP), mà còn ảnh hưởng đến các sản phẩm khác như Google Hình ảnh, Google Video, Google News và cả tính năng Google Discover.
Khi làm SEO, đôi khi bạn sẽ thấy website có những yêu cầu truy cập từ “Googlebot”. Nhưng liệu có chắc đó là Googlebot thật hay chỉ là bot giả mạo? Đây là điều rất quan trọng, bởi nhiều bot xấu thường mạo danh Googlebot để thu thập dữ liệu hoặc tìm cách tấn công website.
Để xác minh, bạn có thể dùng cách tra cứu DNS ngược (reverse DNS lookup) trên địa chỉ IP gửi yêu cầu. Nếu IP đó thực sự thuộc Google, bạn có thể yên tâm rằng đây là Googlebot “chính chủ”.

Một điểm cần lưu ý:
Googlebot thật luôn tuân thủ quy định trong tệp robots.txt. Nghĩa là nếu bạn chặn một đường dẫn, Googlebot sẽ không cố tình truy cập vào.
Trong khi đó, các bot giả mạo hoặc bot xấu thường bỏ qua quy định này và vẫn cố truy cập vào những trang bạn không cho phép.
Nếu phát hiện những bot gian lận hoặc thấy website của mình bị lợi dụng để thao túng kết quả tìm kiếm, bạn có thể báo cáo trực tiếp với Google để được xử lý.
-> Xem ngay: Hướng dẫn SEO web lên Google hiệu quả nhất
Nếu muốn website nhanh chóng được Google bot SEO nhận diện và index, bạn cần tạo điều kiện để Googlebot truy cập và thu thập dữ liệu hiệu quả hơn. Dưới đây là một số cách đơn giản mà bạn có thể áp dụng ngay:
Sửa lỗi kỹ thuật: Các lỗi như 404, liên kết hỏng hay cấu trúc trang bị sai khiến Googlebot khó thu thập dữ liệu. Hãy thường xuyên kiểm tra và khắc phục để website hoạt động trơn tru.
Tối ưu tốc độ tải trang: Website càng nhanh thì Googlebot càng dễ truy cập, từ đó quét nhiều nội dung hơn trong mỗi lần ghé thăm.
Cập nhật nội dung đều đặn: Khi bạn thường xuyên thêm nội dung mới, Googlebot sẽ có xu hướng quay lại website nhiều hơn để thu thập dữ liệu.
Tạo sơ đồ trang web (XML Sitemap): Sitemap giống như bản đồ chỉ đường, giúp Googlebot biết chính xác trang nào quan trọng cần crawl. Đừng quên gửi sitemap lên Google Search Console.
Xây dựng backlink chất lượng: Liên kết từ các website uy tín không chỉ tăng độ tin cậy mà còn “mở đường” để Googlebot phát hiện website của bạn nhanh hơn.
Sử dụng robots.txt và thẻ meta robots: Đây là công cụ để bạn “ra lệnh” cho Googlebot trang nào nên crawl, trang nào không. Do đó, hãy cấu hình đúng để tránh lãng phí crawl budget.
Tối ưu liên kết nội bộ: Hệ thống liên kết nội bộ hợp lý sẽ giúp Googlebot dễ dàng di chuyển giữa các trang, đồng thời cải thiện trải nghiệm người dùng.
Đăng ký Google News: Với các website tin tức hoặc blog, Google News là kênh tuyệt vời để tăng cơ hội được Googlebot truy cập thường xuyên.
Khi làm SEO tổng thể, bạn có thể gặp tình huống Googlebot không thể thu thập dữ liệu website một cách trọn vẹn. Điều này ảnh hưởng trực tiếp đến việc website có được index và hiển thị trên Google hay không. Dưới đây là những lỗi phổ biến và cách khắc phục dễ hiểu mà bạn có thể tham khảo.
Dấu hiệu nhận biết lỗi như Google hiển thị thông báo “Server error”, “Not found” hoặc “Google couldn’t crawl your site”.
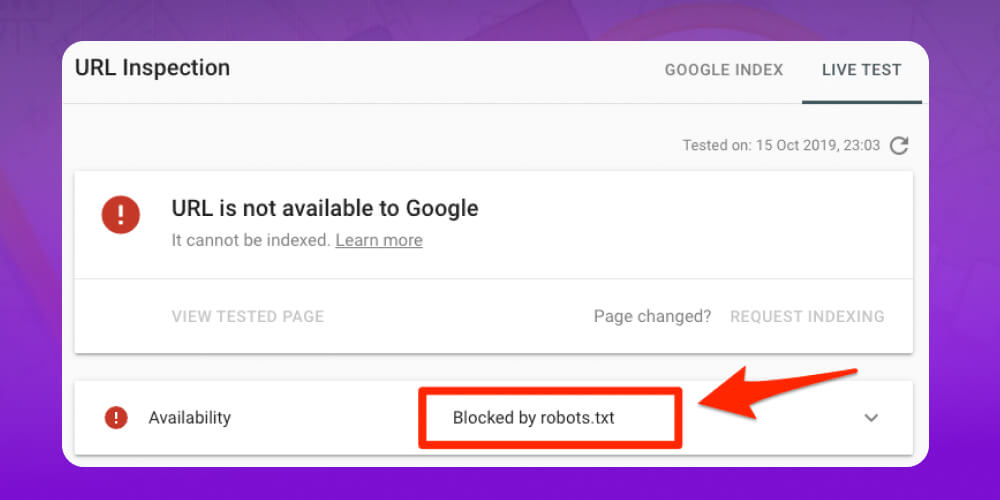
Cách xử lý lỗi URL và robots.txt trong Google Search Console:
Thử mở file robots.txt trên trình duyệt để xem có hoạt động không.
Kiểm tra tường lửa và hosting, tránh chặn Googlebot.
Nếu robots.txt tạo động, kiểm tra lại code tạo file.
Dùng Google Search Console để kiểm tra và xác minh lại bằng công cụ Fetch as Google.
Dấu hiệu nhận biết Googlebot gặp lỗi khi đọc robots.txt, khiến quá trình crawl bị chậm.
Cách xử lý lỗi tỷ lệ truy cập robots.txt:
Nếu tỷ lệ lỗi 100%, có thể website đang chặn Googlebot.
Nếu lỗi dưới 100%, kiểm tra thời điểm lỗi cao nhất, có thể do máy chủ quá tải. Hãy liên hệ nhà cung cấp hosting để tối ưu hoặc nâng cấp gói dịch vụ.
Sau khi sửa xong, hãy dùng Fetch as Google để test lại.
Dấu hiệu nhận biết như Googlebot bị chặn không crawl các URL quan trọng.

Cách xử lý lỗi do file robots.txt sai cấu hình:
Kiểm tra kỹ file robots.txt để chắc chắn không chặn nhầm.
Đảm bảo hosting ổn định, tránh gián đoạn làm Google không truy cập được.
Hy vọng với những thông tin mà chúng tôi vừa cung cấp, bạn đã hiểu rõ hơn về thuật ngữ Googlebot là gì cũng như cách ứng dụng công cụ này để hỗ trợ quá SEO. Với việc hiểu rõ cách hoạt động của Googlebot và tối ưu hóa trang web đúng cách, website có thể đạt được thứ hạng cao trong kết quả tìm kiếm của Google và thu hút được lượng lớn người dùng. Nếu bạn có nhu cầu triển khai dịch vụ SEO website lên TOP Google, vậy thì hãy nhấc máy gọi ngay đến MONA để được tư vấn và nhận báo giá SEO web nhanh chóng.

Founder Phần mềm MONA AI
Người đứng sau các sản phẩm phần mềm AI của MONA, đồng thời phụ trách mảng SEO tổng thể giúp hàng nghìn website lên top bền vững. Nhân trực tiếp nghiên cứu cách Google và các công cụ AI như ChatGPT, Gemini đọc – xếp hạng nội dung, rồi biến thành quy trình SEO đo được cho doanh nghiệp.




Dịch vụ thiết kế
website chuyên nghiệp
Sở hữu website với giao diện đẹp, độc quyền 100%, bảo hành trọn đời với khả năng
mở rộng tính năng linh hoạt theo sự phát triển doanh nghiệp ngay hôm nay!












